Biological Connectivity Patterns as a Blueprint for Efficient Neural Architectures in Reinforcement Learning
This paper investigates whether biologically inspired neural connectivity can guide the design of artificial neural networks (ANNs) that are both computationally efficient and capable of maintaining high performance. The authors focus on a comparison between a biologically inspired architecture known as Neural Circuit Architectural Priors (NCAP) and conventional Multi-Layer Perceptrons (MLPs), which are compressed using two popular techniques: pruning and knowledge distillation. The context for this comparison is a reinforcement learning (RL) locomotion task simulated in the MuJoCo environment.
The motivation stems from a fundamental challenge in ANN design: balancing efficiency and performance. While biological neural systems exhibit sparse, hierarchical, and recurrent structures that evolved to be energy-efficient, modern artificial models often require significant computational resources. Although pruning and knowledge distillation aim to reduce these demands, they themselves are computationally expensive processes. This raises the question: can biologically grounded structural priors outperform or rival conventional compression techniques?
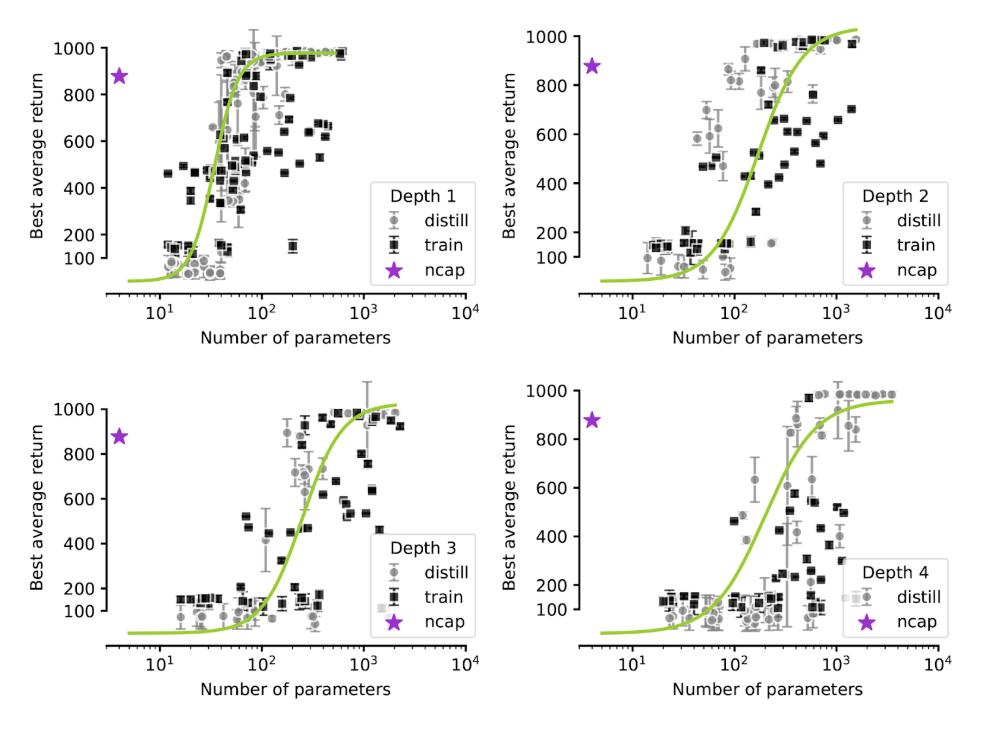
NCAP is a neuro-inspired model based on the simple nervous system of C. elegans. It is designed with innate structural priors and is used here to control a simulated agent’s locomotion. Notably, NCAP achieves high reward in the locomotion task with only four trainable parameters, whereas comparable MLPs require over 100 parameters. Furthermore, NCAP begins performing well almost immediately in training, in contrast to MLPs, which require warm-up periods to reach competent performance.
To rigorously test the performance-efficiency tradeoff, the authors conducted 250 trials with randomly generated MLP architectures. These varied in three dimensions:
- Depth (1 to 4 layers),
- Width (1 to 64 neurons per layer), and
- Sparsity (the proportion of active connections, ranging from fully connected to extremely sparse).
Training was conducted via two methods:
- Proximal Policy Optimization (PPO) to train MLPs from scratch using policy gradients.
- Knowledge distillation, where a high-performing teacher model trained via PPO supervises a smaller student model through a mean squared error (MSE) loss.
Results showed that NCAP occupies a uniquely optimal position in the performance vs. parameter space. It consistently achieved high rewards with far fewer parameters than MLPs. Additionally, well-connected small MLPs outperformed larger but poorly connected MLPs, emphasizing that connectivity structure matters more than size alone.
As MLPs increased in depth, more parameters were needed to achieve similar rewards, revealing that deeper models are not always better and may impose higher learning complexity. Furthermore, in deeper configurations (4 layers), only the distilled models reached high performance, likely because training from scratch took too long under the experimental time constraints (5 million PPO iterations, 2.5 million for distillation).
The study concludes that biological architectures like NCAP offer a compelling blueprint for designing efficient ANNs. It challenges the prevailing strategy of scaling up models for performance, showing that strategic structural design, inspired by evolved neural systems, can yield both efficiency and high reward. These findings pave the way for further integration of neuroscience insights into ANN design, pushing toward models that are both high-performing and computationally sustainable.
This study originated as a project in the NeuroAI course at Neuromatch Academy (July 2024) and was supported by the Impact Scholars Program.